

In the second edition of my book Learning SPARQL, a new chapter titled "A SPARQL Cookbook" includes a section called "Exploring the Data," which features useful queries for looking around a dataset that you know little or nothing about. I was recently wondering about the data available at the SPARQL endpoint http://data.semanticweb.org/sparql, so to explore it I put several of the queries from this section of the book to work.
An important lesson here is how easy SPARQL and RDF make it to explore a dataset that you know nothing about. If you don't know about the properties used, or whether any schema or schemas were used and how much they was used, you can just query for this information. Most hypertext links below will execute the queries they describe using semanticweb.org's SNORQL interface.
I started with what is generally my favorite query, listing which predicates are used in the data, because that's the quickest way to get a flavor for what kind of data is available. Several of the predicates that got listed immediately told me some interesting things:
rdfs:subClassOfshows me that there's probably some structure worth exploring.dcterms:subject(anddc:subject) shows that things have probably been tagged with keywords.ical properties such as dtstart shows that events are recorded.
FOAF properties show that there is probably information about people.
dcterms:title,swrc:booktitle,dc:title,src:title, andswrc:subtitleshow me that works are covered.
An RDF dataset may or may not have explicit structure, and the use of rdfs:subClassOf in this data showed me that there was, so my next query asked what classes were subclasses of what classes so that I could get an overview of how much structure the dataset included. The result showed me that the ontology seemed to be mostly in the swc namespace, which turns out to be the semanticweb.com conference ontology. The site does include nice documentation for this ontology.
The use of the FOAF vocabulary showed me that there are probably people described, but if the properties foaf:name, foaf:lastName, foaf:familyName, foaf:family_name, and foaf:surname are all in there, which should I try first? A quick ego search showed foaf:family_name being used. It also showed that the URI used to represent me is http://data.semanticweb.org/person/bob-ducharme, and because they've published this data as linked data, sending a browser to that URL showed that it described me as a member of the 2010 ISWC program committee.
It also showed me to be a proud instance of the foaf:Person class, so I did a query to find out how many persons there were in all: 10,982.
Given the domain of the ontology and the reason that I was listed, I guessed that it was all about ISWC conferences, so I listed the dc:title values to see what would show up. The query took long enough that I added a LIMIT keyword to create a politer version of that query. Looking at the complete data for one work showed all kinds of interesting information, including an swrc:year value to indicate the year of this paper's conference. A list of all year values showed a range from 2001 right up to 2014, so it's nice to see that they're keeping the data up to date.
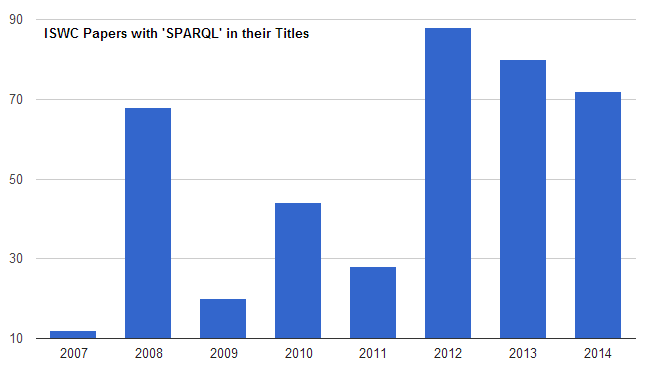
Next, I listed all papers that mention "SPARQL" in their title, with their years. After listing the number of papers with SPARQL in their title each year, I used sgvizler (which I described here last September) to create the chart of these figures shown above.
The use of dcterms:subject and dc:subject was interesting because these add some pretty classic metadata for navigating content. Listing triples that used either, I included LIMIT 100 to be polite to the server in case these properties were used a lot. They are. Doing this with dc:subject shows subjects such as "ontology alignment" and "controlled natural language" assigned to articles. Doing it with dcterms:subject showed it used more the way I might use rdf:type, indicating that something is an instance of a particular class: for example, swc:Chair and swc:Delegate each have dcterms:subject values of http://dbpedia.org/resource/Role.
My interest in taxonomies (spurred by my work with TopQuadrant's TopBraid EVN) led me to look harder at the dc:subject values. They're string values, and not instances of something like skos:Concept, so they have no hierarchical relationship or other metadata themselves. I'm guessing that this is because key phrases assigned to conference papers are more of a folksonomy, in which people can make up their own key phrases as they wish. Either some people must have been aware of other key phrases in use or some were added automatically, because, while counting how many different ones there were came up with 3,594, a query to see which were the most popular showed that "Corpus (creation, annotation, etc.)" was far and away the most used, with 506 papers having that subject.
I could go on. Call me a SPARQL geek, but I really enjoy looking around a data set like this, especially when (as the presence of the papers for ISWC 2014 shows) the data is kept up to date. For people interested in any aspect of semantic web technology, the ability to look around this particular dataset and count up which data falls into which patterns is a great resource.
Please add any comments to this Google+ post.