The following ran in the April 2005 issue of Dr. Dobbs magazine and is reproduced by permission.
If you can refer to something by a URI, you can use RDF to assign a property name/value pair to it. (And if it has no URI, you can just make one up!)
By Bob DuCharme bob@snee.com
Resource Description Framework (RDF) is a W3C standard format for storing arbitrary data on the web and elsewhere. It's particularly good for storing metadata about files and other machine-accessible resources. You can store handfuls of RDF inside the resources they describe, outside of them, in relational databases, in XML, or any place you like, and then easily combine these handfuls into a database that you can use for queries, reports, and graphs.
The ability to exchange and combine RDF from different places across the Web has made it a cornerstone of the W3C's "Semantic Web" plans, and it's already proving itself very helpful in accomplishing much more mundane tasks. Whether your data is structured or unstructured, typed or untyped, centralized or distributed, RDF just may make the job of storing and using that data easier.
RDF gives you a machine-readable way to say anything about anything. The basic data structure upon which everything else is built is called a triple, and is described using rather grammatical terminology: (subject, predicate, object). For many applications, you can think of it as (object, property-name, property-value).
Listing One shows the file rdf1.nt, which has three triples written in the n-triples notation. This is the simplest, if the most verbose, of the three syntaxes currently available for writing RDF data. Each triple's subject, predicate, and object are written out separated by whitespace with a period at the end. Technically, each triple should be written on a single line, but the cwm program, which can read and translate between RDF syntaxes, doesn't seem to mind the carriage returns.
The triples in Listing One make these three statements:
The resource at URI http://level2.cap.gov/documents/u_090403105113.doc has a title of "MISHAP REPORT FORM."
The resource at URI http://level2.cap.gov/documents/u_090403105113.doc has a format of "Microsoft Word 97".
The resource at URI http://level2.cap.gov/index.cfm?nodeID=5464 links to the resource at URI http://level2.cap.gov/documents/u_090403105113.doc.
u_090403105113.doc is a file I found with a Google search. I can't write or edit anything on its server, but that doesn't stop me from creating RDF-based metadata for that resource and storing it on my own web site where any process with access to the Internet can find it. The metadata shown here for the resource u_090403105113.doc looks sensible enough, but if I wanted to use the same RDF syntax to say that u_090403105113.doc has a goofinessFactor of 3.2, it would be just as easy as using RDF to identify its title or format. I can add any metadata I want to u_090403105113.doc, because I can identify it with a URI.
RDF requires that the subject of every triple be a URI. The original idea was that you'd use RDF to add metadata to web resources, which are identified by URIs, but you can also use URIs that don't necessarily represent a retrievable resource. For example, if you want to identify employee number 4239 in your company as http://www.your-company-name.com/somepath/empnum#4239, you can. As with Java package naming, the convention of building these identifying URIs from domain names means that when you control a domain name you can control the conventions used to build names that use it.
When possible, use an existing URI instead of making one up, because the use of known URIs makes it easier to find and combine data about identified resources. For example, a URI for the book "The C Programming Language" could be the Amazon URL http://www.amazon.com/exec/obidos/ASIN/0131103628. If you're not writing an application for the on-line retailer, though, it would be even better to use a URI less dependent on a specific company's practices, which is why I refer to these as "URIs" instead of "URLs": in addition to URLs, you can also use a URN, or "Uniform Resource Name." The URI urn:isbn:0131103628 uses a format developed jointly by the International ISBN Agency and the National Library of Finland, making it an even better candidate to identify "The C Programming Language" in an RDF triple.
RDF predicates must also be URIs. If a triple says that a given entity has a "title" of "Wedding Singer," how do we know whether that's a job title or a movie title? Making it a full URI such as http://purl.org/dc/elements/1.1/title makes it clearer that this is the title of a work and not a job. This particular URI is from the Dublin Core Metadata Initiative, an open forum for creating interoperable metadata standards. As with subjects, if a URI isn't available to express the predicate you need, you can make one up using a domain for which you can dictate usage conventions, as I did with http://www.snee.com/ns/rel#linksTo in Listing One.
The third part of an RDF triple, the object, can be either a URI or a string literal. The first two triples in Listing One have the literals "MISHAP REPORT FORM" and "Microsoft Word 97" as objects, and the third has the URI http://level2.cap.gov/documents/u_090403105113.doc as its object. The fact that a given URI can be the subject of some triples and the object of others is the basis of much of RDF's power, because an inferencing engine can determine new facts from a combination of triples. For example, if someone asked "Does http://level2.cap.gov/index.cfm?nodeID=5464 link to any Word files, and if so, what are the titles of those files?", no single triple in Listing One can provide an answer, but the combination of the three can.
Because you can do more with URIs than with simple strings in RDF, the n-triples notation delimits them with < and > instead of quotation marks to make it clear that they're URIs.
RDF's ability to assign any predicate/object pair to any subject makes it an ideal format for a freeform database. For example, if my address book lists each person's name, address, phone number and e-mail address, and I want to add a single new field for one person, it's just one more triple to add, with no schema revision to contend with. (The W3C does have a specification for RDF schema available, but RDF schemas are more commonly used to provide additional information about data, such as data types and domains, than to constrain the entered data.) If I add a triple saying that Nick Charles has a dogName value of "Asta", displaying Nick's information will then show the dog's name along with Nick's address and other information, even if no one else in my address book ever had a dogName property assigned.
This flexibility is one reason that the Open Source Applications Foundation's Chandler personal information manager project uses RDF as a native format to store data. It's also the key difference between RSS 1.0 and its competitors: because of its RDF basis, adding new classes of data to a given RSS 1.0 item doesn't require an extension to the RSS specification—the use of RDF builds extensibility right in.
The flexibility of RDF storage also makes it popular for adding metadata to disk files that don't have an obvious slot for metadata, especially if you need to aggregate this data into collections. With your files as subjects, think of the predicate/object pairs as being like javadoc doc tags, except that you can make up your own tags and use them for any kind of file, Java source or otherwise.
You can also store this metadata inside or outside of the files they describe. Binary formats such as bitmapped images and proprietary formats such as the Word file referenced in Listing One are good examples; metadata about source code and Linux RPMs, like the data in the file at http://download.freshmeat.net/backend/fm.rdf, are another.
The simplicity and scalability of the triplet structures make RDF a popular format for data interchange. When you download information about the DMOZ open directory project's directory structure, it's in RDF. The Mozilla web browser uses it as a native format for much of its user interface implementation, and the MusicBrainz metadatabase uses RDF as the format for downloads from their massive database of albums, artists, and songs.
Take two files of RDF triples written in the n-triples syntax, or in the related Notation 3 described below, append one file to the other, and you've just merged two databases. This ease of data aggregation makes RDF a popular format for storing distributed data that is collected whenever some application needs an updated set. In the experimental Friend of a Friend (FOAF) project, people store personal data in an RDF/XML file (the first of the two additional RDF syntaxes that we'll review below) on their web site. For example, mine is at http://www.snee.com/bob/foaf.rdf. Because these files include the URIs of friends' FOAF files, the growing collection is linked into a distributed database, and various applications have been developed to crawl them and look for patterns.
A more practical example of an RDF distributed database is the one that tracks the W3C's collection of technical reports, which include everything from finished specs such as the official HTML and XML Recommendations to in-progress specs to new proposals submitted by member companies. These documents, which number over 400 and were created by over 500 editors, must conform to a common format, with metadata assigned to each document such as its title, date of publication, and its editors' names and e-mail addresses. If someone logged in to a central relational database and updated the appropriate record when metadata about one of the reports changed, it would be nice, but unrealistic. Instead, each document has an accompanying file of metadata in RDF/XML. This lets automated processes replace the human labor that was once necessary to check a technical report's readiness for the next step in its workflow. Along with speeding up the publishing process, this has provided other bonuses: simple HTTP requests can combine the data into an updated database that the W3C uses as the basis of reports and graphs to measure productivity, look for trends, and plan budgets.
Dan Connolly of the W3C finds that this setup accomplishes a great deal without putting new pressures on the work habits of the diverse, world-wide group creating these reports. According to Connolly, "In managing W3C technical reports, the data flows through all sorts of different peers, from the editors of the specs to the W3C webmaster to membership databases and online forms. RDF allows us to integrate the data with minimal impact on the way people work; we don't have to constrain everybody to one central database store or even one central database schema."
Two other syntaxes for RDF triples are available to more easily integrate RDF into various classes of applications. RDF/XML is an XML format; Listing Two shows the XML equivalent of the triples from Listing One.
XML offers many options for encoding triples, and Listing Two demonstrates several. One popular structure is an rdf:Description element with the subject of one or more triples in an rdf:about attribute. The rdf:Description can store predicate/object pairings for that subject as child elements with the predicate providing the child element's name and the PCDATA content of this child element providing the object value. The first rdf:Description element in Listing Two has two such children, corresponding to the first two triples in Listing One. For the "format" predicate, an xmlns attribute stores the URI that XML uses to identify the element name's namespace. When you have many elements, this can get verbose, so the title predicate takes advantage of the XML syntax for declaring a namespace prefix to stand in for a namespace URI (the xmlns:dc="http://purl.org/dc/elements/1.1/" attribute setting in the rdf:RDF start-tag) so that the title start-tag can be written as <dc:title>. This way, the title element doesn't need an xmlns attribute to identify its namespace. An element name of dc:format for the preceding element would have made its xmlns attribute unnecessary as well.
You can also store a predicate/object pair in an rdf:Description element by including it as an attribute setting. For example, if you removed the dc:title element from Listing Two's first rdf:Description element and added dc:title="MISHAP REPORT FORM" to the rdf:Description element's start-tag, the document would still represent the same set of RDF triples.
If you removed the sn:linksTo element from the second rdf:Description element, however, and added an sn:linksTo="http://level2.cap.gov/documents/u_090403105113.doc" attribute to its parent element's start-tag, it wouldn't be the same thing. Listing Two's sn:linksTo element doesn't store its object value as PCDATA between start- and end-tags, but as the value of an rdf:resource attribute, essentially saying "This value is a resource identifiable by a URI, and not just some string that happens to begin with 'http://'." In n-triples notation, it's the difference between enclosing the value in quotation marks and enclosing it in angle brackets. It's a big difference, because an object that is a resource can be treated as the subject of other triples. Knowing that the object of this triple is the same resource as the subject of the first two triples is what lets an inferencing engine determine whether http://level2.cap.gov/index.cfm?nodeID=5464 links to any Word 97 files.
An increasingly popular RDF syntax that combines the directness of n-triples with the abbreviation tricks of RDF/XML is called Notation 3, or n3. Developed by Tim Berners-Lee, it resembles n-triples but allows stacking of predicate/object pairs with a single subject by delimiting them with semicolons, and it offers a namespace abbreviation convention similar to XML's. The syntax in Listing Three's representation of the triples from Listings One and Two should be intuitive enough to anyone who's seen the first two listings.
n3 isn't just about defining data, though; it offers some bonuses that make it especially popular for RDF development. You can specify rules, such one saying that if (X, isFatherOf, Y) and (Y, isFatherOf, Z) then (X, isGrandfatherOf, Z). You can define equivalences, such as that the predicate isDadOf is equivalent to isFatherOf, so that if (Y, isDadOf, V) in addition to the previous statements, then we can infer that (X, isGrandfatherOf, V). These features enable the kind of inferencing that make n3 a fertile ground for more advanced RDF development, such as the Semantic Web work.
We've seen that one triple's object can be the subject of other triples, and that predicates must be URIs, so a given triple's predicate can itself be the subject or object of other triples. If you try to visualize the complex structure that may result from this kind of node sharing, you're best off doing it with a graph. Graphs are popular in the RDF world, complete with free utilities to generate them for you. Figure One shows a graph of our example set of triples.
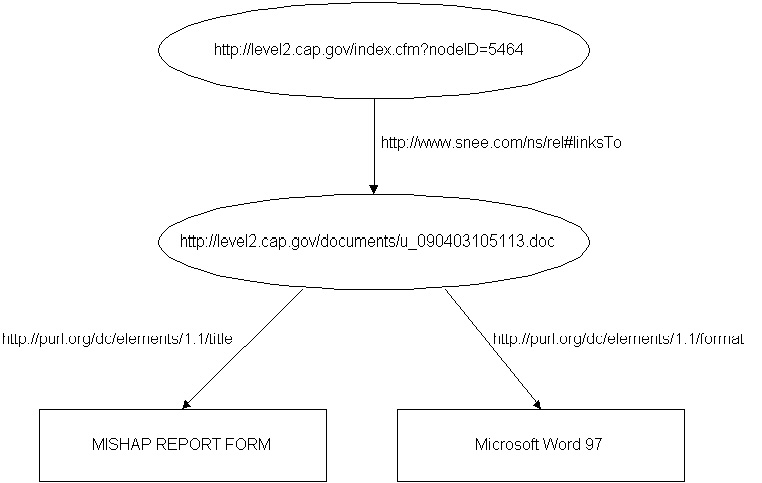
Figure 1: Graph of Triples from Listing One
Many have noted the resemblance of RDF graphs to Entity-Relationship diagrams. When entities can be represented by URIs, RDF makes an ideal candidate for storing ER diagrams as machine-readable text. RDF is actually more flexible than classical ER diagrams, because there's nothing to prevent you from making one of the "relationships"—that is, one of the predicates, as represented by its URI—the subject or object of triples.
This ability to treat predicates as first-class objects provides other advantages. By using the W3C's Web Ontology Language (OWL), you can define equivalencies between predicates that make it easier to combine databases without revising one database to have the same schema as the other. For example, if you define uspo:zipcode and mycorp:zip as being equivalent, a search on addresses with a mycorp:zip value of "11217" will also return addresses with a uspo:zipcode value of "11217". Along with the simplicity of combining two sets of triples into a single new database, this feature makes RDF an even more attractive approach to aggregating distributed data not controlled by a central authority. (If you have an ontology to manage you may find, as Sun Microsystems did for their enterprise ontology management, that RDF triples are the best way to track the entries of their ontology.)
Libraries for parsing and using RDF are available in Java, C, C#, Perl, PHP, Lisp, Tcl/TK, and especially Python. (The cwm program mentioned above was written in Python, although its use requires no knowledge of Python.)
Listings Four and Five show two short Python programs that use RDFLib, an open-source library that can parse all the various permutations of XML/RDF and then store them in an object called a TripleStore. With the inclusion of Sleepycat's Berkeley DB in Python 2.3 and later, you need very little code to amass a huge collection of triples in a persistent, disk-based TripleStore, which makes it easy to build useful applications around an RDF database.
The addRDF2DB.py program in Listing Four adds the triples in the named XML/RDF file to the disk-based TripleStore named as the second parameter. After checking that the appropriate parameters were entered, the program defines and opens a TripleStore object and then uses the TripleStore load method to load the triples to the store with a single line of code. Finally, it prints a message about whether it was successful and closes the store.
Repeated use of addRDF2DB.py with different RDF/XML files in the first parameter and the same TripleStore name in the second parameter will build a larger and larger database. Listing Five shows getSubjectData.py, a Python script that gets all the predicate/object combinations for a given subject (or, put another way, all of the property name/value pairs for a given object) out of the specified disk-based TripleStore. After performing setup steps similar to those in Listing Four, a short for loop uses the predicate_objects method of RDFLib's TripleStore class to retrieve all of the predicate/object pairs for the URI passed as a parameter. (To treat it as a URI, the RDFLib URIRef method casts the string passed for the URI parameter into a URI object.).
Adobe defined their XMP (Extensible Metadata Platform) standard using a subset of RDF, and specifications and an SDK for XMP are available for free on their website. More and more of their products let you assign metadata using XMP-defined predicates or your own arbitrary metadata to Acrobat PDF files, Adobe Illustrator and PostScript files, as well as many non-Adobe formats that their products can edit such as JPEG, TIFF, and GIF files. In what is now my ultimate test for adding arbitrary metadata, I used a 30-day tryout version of Adobe Acrobat 6.0 Professional to assign an http://www.snee.com/ns/whatever/goofinessFactor value of "3.6" to a PDF file that I had created with the open source OpenOffice program. Viewing the resulting PDF file with a text editor showed that the appropriate RDF/XML rdf:Description element had been added to the PDF file; the results of a Save As XML command showed the same rdf:Description element in an xmpmeta element stored as the document's header.
The Creative Commons effort to do for content re-use rights what the free software and open-source movements have done for source code licensing has made a much less frivolous use of the same capability. Digital rights management parameters are an increasingly important category of metadata, and the creative commons website (http://www.creativecommons.org) has forms that generate RDF describing the re-use rights that you want to assign to your text, image, music, or other creative work. It also includes instructions for using Adobe software to add this RDF to a block of XMP metadata stored in a JPEG file, Acrobat PDF file, or other file that an Adobe product can edit. It's almost ironic that, despite RDF's strength at storing out-of-line metadata, these tools are making it easier and easier to embed it within binary files. This ability to embed both standardized and arbitrary metadata within digital assets will make those assets easier to store, track, and maintain.
People who use RDF are seeing more potential applications for it every day, and the available open source libraries for creating and parsing it mean that building applications around RDF data can require very little code. It's already making straightforward, everyday tasks such as tracking the metadata associated with widely distributed resources easier, and its prominent position in the evolving Semantic Web means that it will play a key role in some of the more interesting work of the future.
# rdf1.nt: sample RDF file in n-triples format. <http://level2.cap.gov/documents/u_090403105113.doc> <http://purl.org/dc/elements/1.1/title> "MISHAP REPORT FORM". <http://level2.cap.gov/documents/u_090403105113.doc> <http://purl.org/dc/elements/1.1/format> "Microsoft Word 97". <http://level2.cap.gov/index.cfm?nodeID=5464> <http://www.snee.com/ns/rel#linksTo> <http://level2.cap.gov/documents/u_090403105113.doc>.
<rdf:RDF xmlns:sn="http://www.snee.com/ns/rel#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://level2.cap.gov/documents/u_090403105113.doc">
<dc:title>MISHAP REPORT FORM</dc:title>
<format xmlns="http://purl.org/dc/elements/1.1/">Microsoft Word 97</format>
</rdf:Description>
<rdf:Description rdf:about="http://level2.cap.gov/index.cfm?nodeID=5464">
<sn:linksTo rdf:resource="http://level2.cap.gov/documents/u_090403105113.doc"/>
</rdf:Description>
</rdf:RDF>
# This is an n3 comment line. @prefix : <http://snee.com/ns/rel#> . @prefix dc: <http://purl.org/dc/elements/1.1/> . <http://level2.cap.gov/documents/u_090403105113.doc> dc:format "Microsoft Word 97"; dc:title "MISHAP REPORT FORM" . <http://level2.cap.gov/index.cfm?nodeID=5464> :linksTo <http://level2.cap.gov/documents/u_090403105113.doc> .
#! /usr/bin/python
# addRDF2DB.py: add triples from XML file to disk-based store.
import sys
# Import RDFLib's InformationStore (a Sleepycat BTree backed
# TripleStore with contexts).
from rdflib.InformationStore import InformationStore as TripleStore
if len(sys.argv) != 3:
print "Enter\n\n addRDF2DB.py filename.rdf dbName\n"
print "to add triples from filename.rdf to Sleepycat database dbName."
sys.exit()
RDFfile = sys.argv[1]
db = sys.argv[2]
store = TripleStore()
store.open(db)
try:
store.load(RDFfile)
print RDFfile + " successfully loaded to " + db + "."
except:
print "Problem parsing " + RDFfile + "."
store.close()
#! /usr/bin/python # getSubjectData.py: list triples for supplied subject. import sys # Import RDFLib's InformationStore (a Sleepycat BTree backed # TripleStore with contexts). from rdflib.InformationStore import InformationStore as TripleStore from rdflib.URIRef import URIRef if len(sys.argv) != 3: print "Enter\n\n getSubjectData.py dbName URI\n" print "to get data for the subject identified by URI " print "from the Sleepycat database dbName." sys.exit() db = sys.argv[1] subjectURI = sys.argv[2] store = TripleStore() store.open(db) for docInfo in store.predicate_objects(URIRef(subjectURI)): print docInfo store.close()